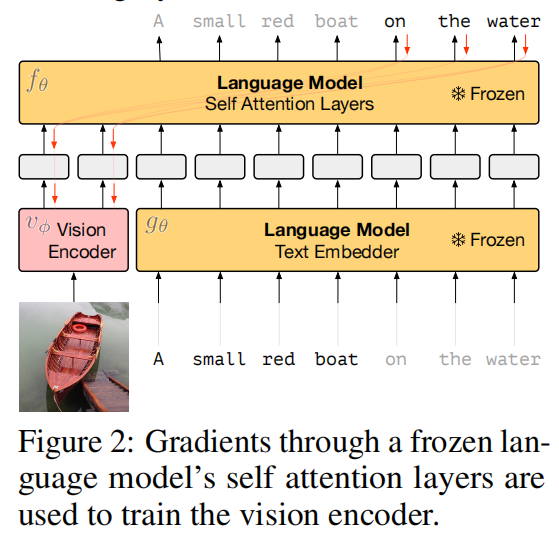
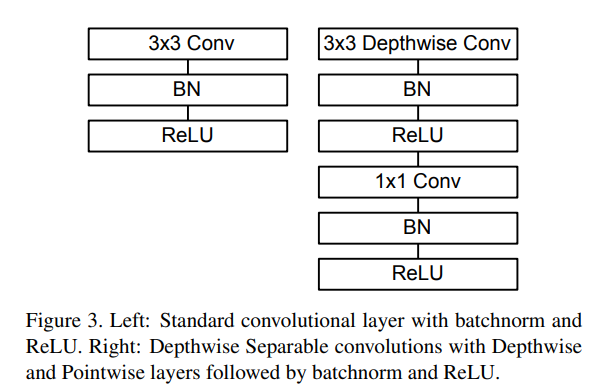
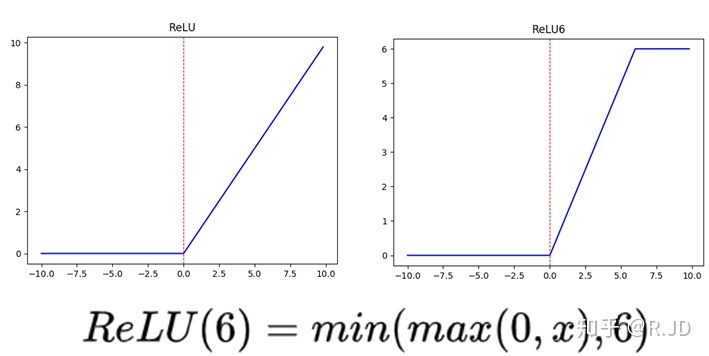
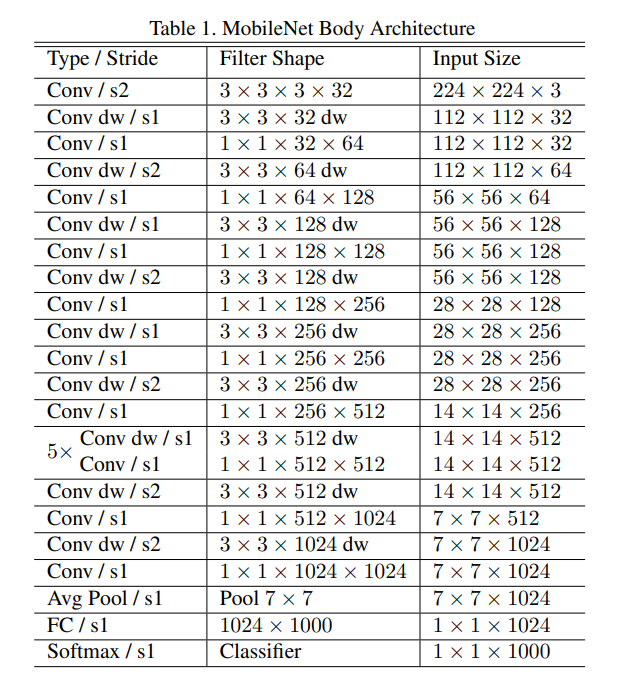
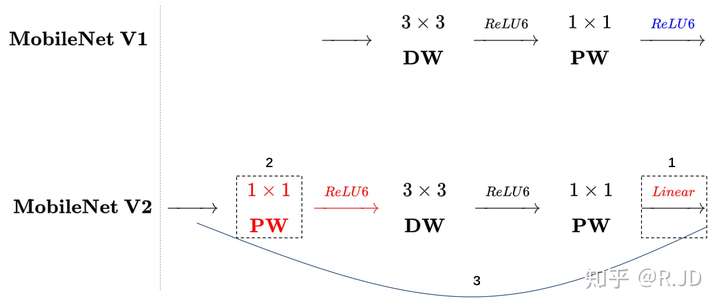
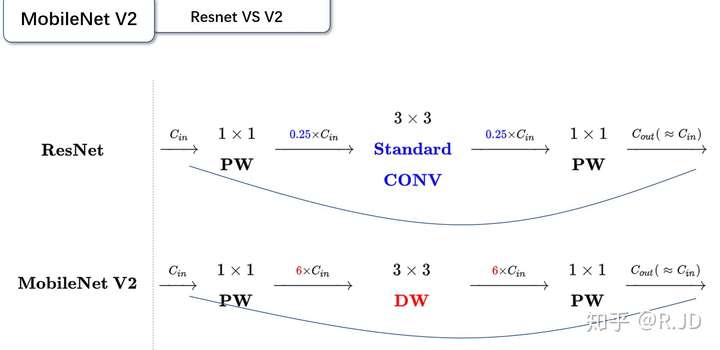
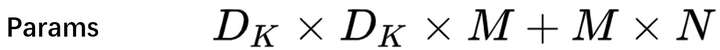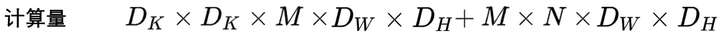What & How it tackles: an overview
-
Transformers are expressive(contain no inductive bias that prioritizes local interactions compared to CNNs)
-
However, long sequences are computationally infeasible in Transformers (e.g hi-res images can result in an embedding with so high dimensions which makes the computations cost high)
-
2 Stage Method: CNNs can learn a context-rich vocab of image constituents (and lower the dimension)
-
Transformers in turn efficiently model their composition
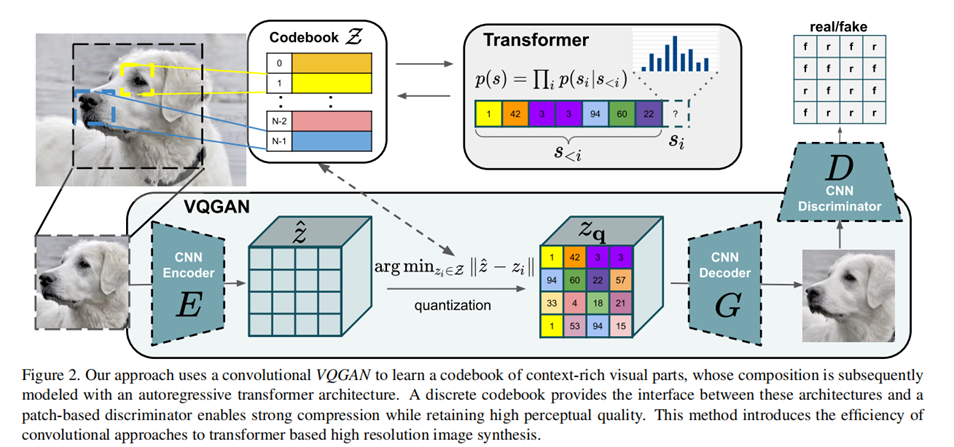
Model overview of #VQGAN
-
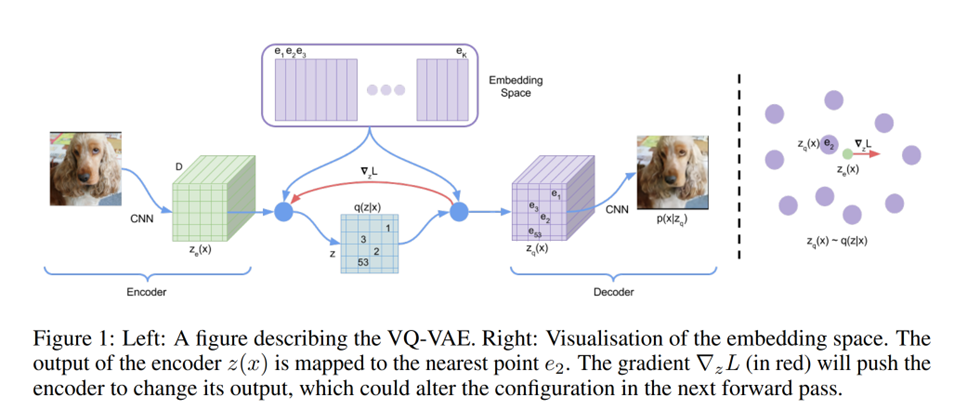
Model architecture of VQVAE
-
Model architecture of VQGAN
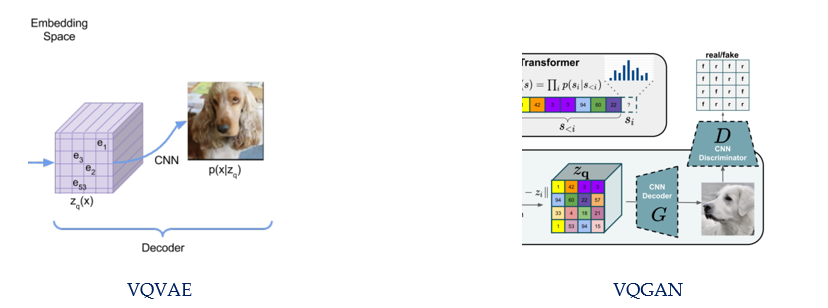
VQGAN vs. VQVAE: CNN Encoder

-
Same Encoder(CNN)
-
Turning an image to Tensors
VQGAN vs. VQVAE: Codebook

-
VQVAE finds the nearest embedding e_k in [Embedding Space] and codebook updates with the encoder(loss)
-
VQGAN uses a 2-stage approach
-
Stage 1: use VAE to learn the Codebook Z
-
Stage 2: use Transformer(GPT-2) to generate latent code
-
VQGAN vs. VQVAE: Decoder side
-
VQVAE sends z_q (x) into CNN decoder to generate output
-
VQGAN sends z_q (x) into CNN decoder to generate output, too. But with a CNN discriminator (GAN)
-
Patch-based (high-res images are too large)
-
Sending signals to codebook, encoder and decoder
Diving into VQGAN: The Loss
Loss function in Stage 1 (use VAE to learn the Codebook)
-
Loss function in VQ is:
\[\begin{aligned} \mathcal{L}_{\mathrm{VQ}}(E, G, \mathcal{Z})=\|x-\hat{x}\|^{2} +\left\|\operatorname{sg}[E(x)]-z_{\mathrm{q}}\right\|_{2}^{2} +\left\|\operatorname{sg}\left[z_{\mathrm{q}}\right]-E(x)\right\|_{2}^{2} . \end{aligned}\] -
Here, \(\|x-\hat{x}\|^{2}\) corresponds to Reconstruction Loss (GAN), the \(\left\|\mathrm{sg}[E(x)]-z_{\mathrm{q}}\right\|_{2}^{2}\) trains the codebook, and \(\left\|\mathrm{sg}\left[z_{\mathrm{q}}\right]-E(x)\right\|_{2}^{2}\) trains the encoder. P.S. the \(s g[x]\) means stopgradient, which means we don’t calculate the gradient of the input \(x\).
-
Loss function in Discriminator \(D\) (GAN) is: \(\mathcal{L}_{\mathrm{GAN}}(\{E, G, \mathcal{Z}\}, D)=[\log D(x)+\log (1-D(\hat{x}))]\)
-
Then the whole model can be described as:
\[\begin{aligned} \mathcal{Q}^{*}=\underset{E, G, \mathcal{Z}}{\arg \min } \max _{D} \mathbb{E}_{x \sim p(x)} & {\left[\mathcal{L}_{\mathrm{VQ}}(E, G, \mathcal{Z})\right.} \left.+\lambda \mathcal{L}_{\mathrm{GAN}}(\{E, G, \mathcal{Z}\}, D)\right] \end{aligned}\] -
We combine the loss of generator and discriminator
\[\begin{aligned} \mathcal{Q}^{*}=\underset{E, G, \mathcal{Z}}{\arg \min } \max _{D} \mathbb{E}_{x \sim p(x)} & {\left[\mathcal{L}_{\mathrm{VQ}}(E, G, \mathcal{Z})\right.} \left.+\lambda \mathcal{L}_{\mathrm{GAN}}(\{E, G, \mathcal{Z}\}, D)\right] \end{aligned}\] -
And here, lambda is used to balance the 2 losses:
\[\lambda=\frac{\nabla_{G_{L}}\left[\mathcal{L}_{\mathrm{rec}}\right]}{\nabla_{G_{L}}\left[\mathcal{L}_{\mathrm{GAN}}\right]+\delta}\] -
And \(\delta=10-6\) prevents this lambda from \(0 / 0\). (numerical stability)
-
\(\nabla \mathrm{GL}[\cdot]\) denotes the gradient of its input w.r.t. the last layer \(\mathrm{L}\) of the decoder.
Diving into VQGAN: Stage 2
Learning the Composition of Images with Transformers
-
In Stage 1 we successfully learn a good codebook(it can generate a good image which passes the discriminator!)
-
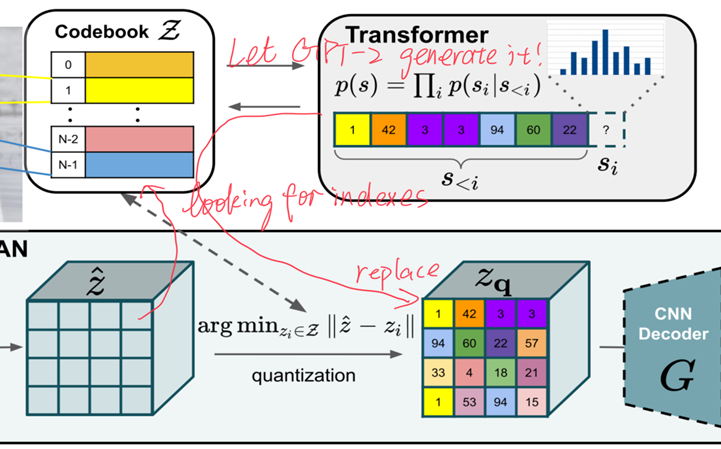
Then we use the codebook to replace E(x) i.e. 𝑧 ̂. Take a look back at the Figure 2 (GPT-2 autoregressively generate the next code in 𝑧_𝑞).
-
What about the large images? (remember we want to generate hi-res images!)
-
If the z_q has too much slots to fill, in Transformer it will be a huge array which takes up a lot of resources!
-
So we need to do some blocking things – a sliding attention window:
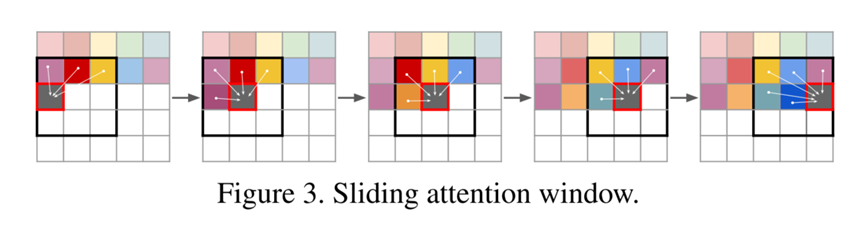
-
In every sliding window, we generate the next code autoregressively using the information within it (resource-friendly).
-
Another thing is conditioned synthesis: We can give the model some information (which is called Condition) to guide it in generating images.
-
The Condition can be from a single label to even another image.
-
How it operates:
- To pass spatial conditioning information to the transformer a second VQGAN is learned to obtain additional tokens that are simply prepended to the main tokens before going into the transformer.



















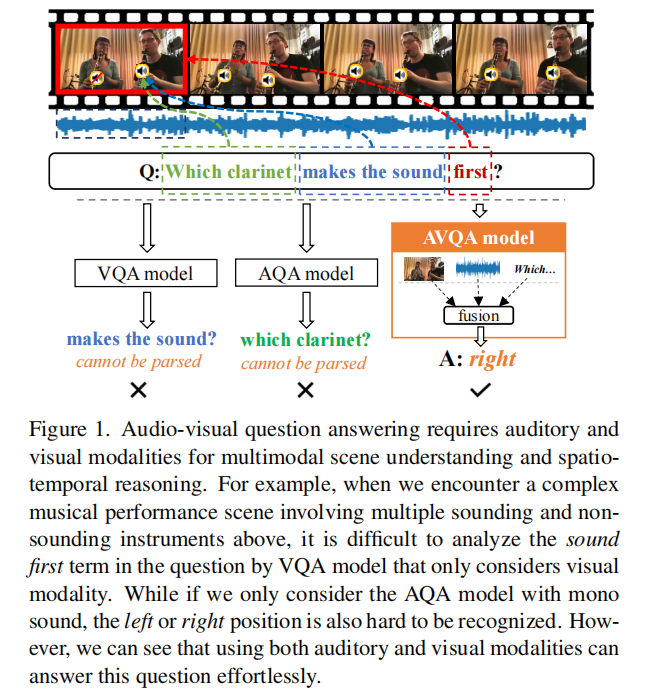
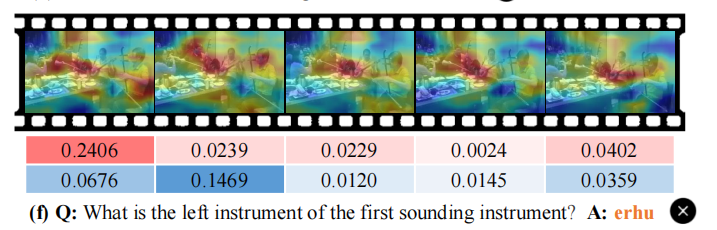
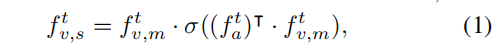
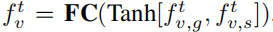 其中 FC 表示全连接层。 然后,结合视觉和音频表示来预测视听对是否匹配:
其中 FC 表示全连接层。 然后,结合视觉和音频表示来预测视听对是否匹配: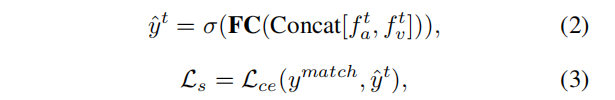
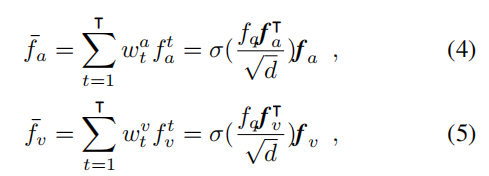
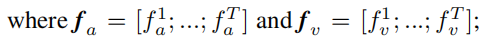 d 是与特征维度大小相同的缩放因子。 显然,该模型将为与所提出的问题更相关的音频和视频片段分配较大的权重。 因此,基于问题的音频/视觉上下文嵌入更能预测正确答案。
d 是与特征维度大小相同的缩放因子。 显然,该模型将为与所提出的问题更相关的音频和视频片段分配较大的权重。 因此,基于问题的音频/视觉上下文嵌入更能预测正确答案。