This is my reading note for MobileNets series.
MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications
Abstract
- introduce two simple global hyperparameters that efficiently trade off between latency and accuracy
- These hyper-parameters allow the model builder to choose the right sized model for their application based on the constraints of the problem.
Conclusion
-
proposed a new model architecture called MobileNets based on depthwise separable convolutions.
-
investigated some of the important design decisions leading to an efficient model.
-
demonstrated how to build smaller and faster MobileNets using width multiplier and resolution multiplier by trading off a reasonable amount of accuracy to reduce size and latency.
-
compared different MobileNets to popular models demonstrating superior size, speed and accuracy characteristics
-
concluded by demonstrating MobileNet’s effectiveness when applied to a wide variety of tasks.
Depthwise Separable Convolution
传统卷积的计算量:(D_FD_FD_KD_KM*N)。其中DF为特征图尺寸,DK为卷积核尺寸,M为输入通道数,N为输出通道数。
Depthwise convolution
- 卷积核拆分成单通道
- 对每一通道进行卷积操作
计算量 (D_FD_FD_KD_KM)
Pointwise convolution
- 用 1x1 的卷积核对输入特征图进行卷积操作
计算量 (D_FD_FM*N)
总计
比较:
总参数量
- Depthwise convolution 的卷积核尺寸是 Dk*Dk*M.
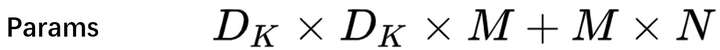
总计算量
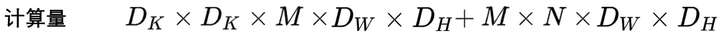
卷积层

如果看源码的话可以发现这个 ReLU 层用的是 ReLU6:
# from https://github.com/tensorflow/models/blob/master/research/slim/nets/mobilenet/mobilenet_v2.py
activation_fn: Activation function to use, defaults to tf.nn.relu6 if not
specified.

- 在移动设备上由于是 float16 的,ReLU激活范围不加限制的话输出范围太大,float16无法精确描述如此大范围数值,精度损失。
- 把boundary设置为6,则低精度也有很好的数值分辨率。

MobileNetV2: Inverted Residuals and Linear Bottlenecks
Abstract
- inverted residual structure
Conclusions and future work
- a very simple network architecture that allowed us to build a family of highly efficient mobile models.
- the proposed convolutional block has a unique property that allows to separate the network expressiviness (encoded by expansion layers) from its capacity (encoded by bottleneck inputs). Exploring this is an important direction for future research.
V1 存在的问题
ReLU 6 造成信息丢失
-
把一个流形用 random matrix T 映射到 n 维空间后用 ReLU 处理,再用 T 的逆矩阵映射回来在低维度造成了信息丢失。高维度看起来其实是还可以的。

-
最后的那个 ReLU 被换成线性激活函数 -> Linear BottleNeck
如果输入通道较少,深度卷积只能工作在低维度,效果不好
- 先用 PW 卷积升维度,再在一个更高维度的空间中进行卷积操作。(Expansion Layer)
其他
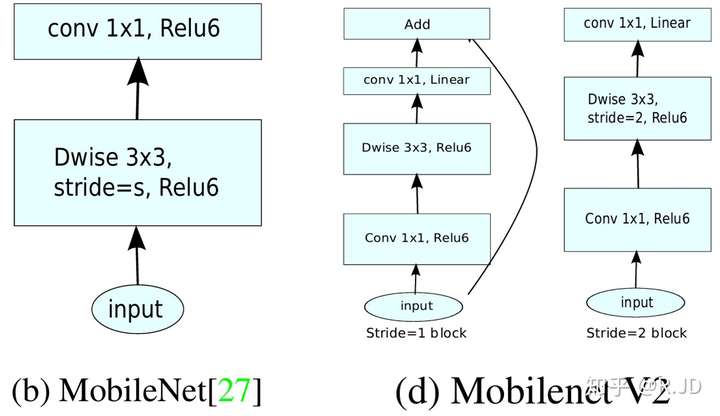
ShortCut 结构
类似 ResNet 复用特征:
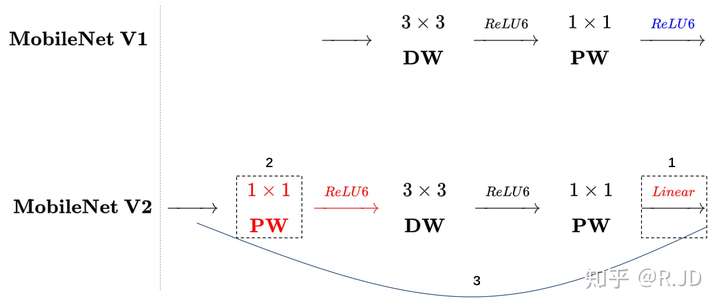
另外你也可以看到尾部的 RELU6 被换成了 Linear。
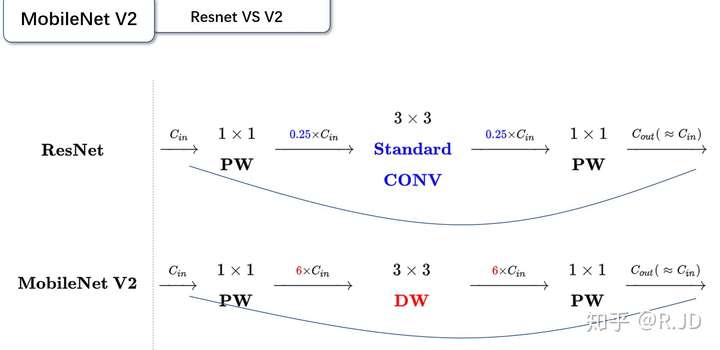
与 ResNet 相比,MobileNet V2 由 ResNet 的 0.25 降维变成了 6 倍升维,这样实际上 MobileNet 在网络中间的部分维度是比较大的。 具象起来就比较像纺锤结构。而 Resnet 中间的维度比较小。这样想象一下就可以理解 MobileNet 为什么用 Inverted residuals 这个名字了。
V2 的 block:
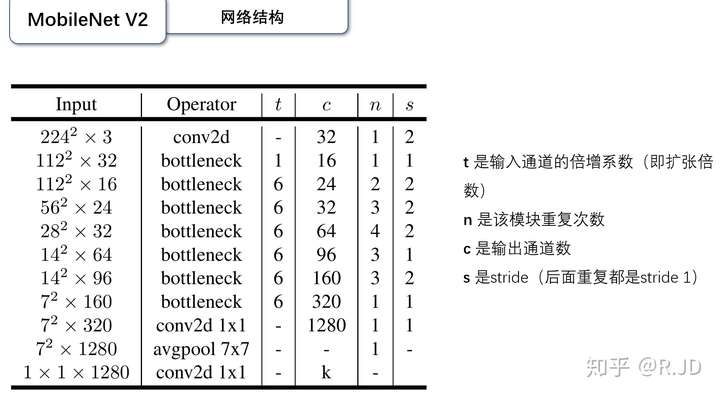
网络结构:
Searching for MobileNetV3
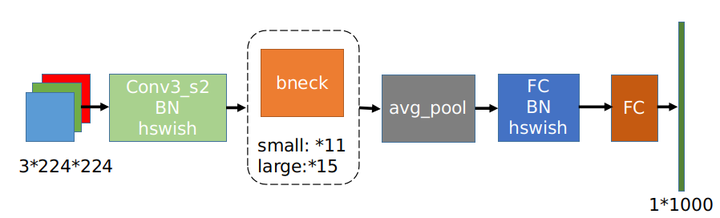
Spotlights
-
NAS(hardware-aware network architecture search)
- NetAdapt 算法
- Good ideas from V1:
- Depthwise Separable Convolution
- Good ideas from V2:
- resource-efficient block with inverted residuals and linear bottlenecks.
-
Squeeze-And-Excite
- h-swish(x) in replace of ReLU6
- ReLU6(x+3)/6 in simulation of sigmoid in SE module
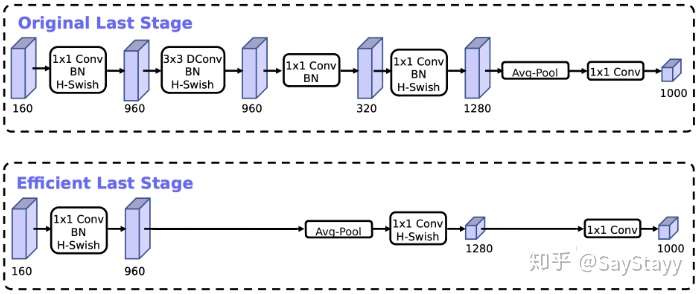
- change the head of MobileNetV2
Small 和 Large 的版本参数
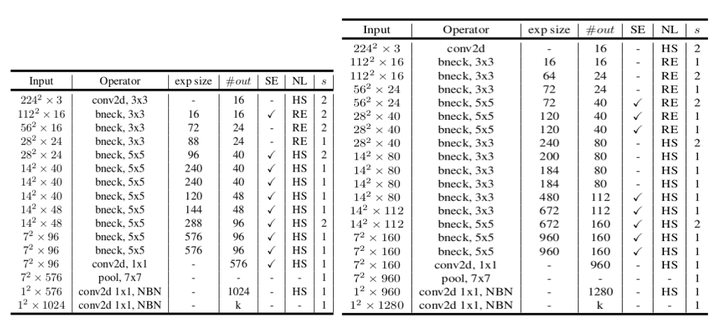
- SE denotes whether there is a Squeeze-And-Excite in that block.
- NL denotes the type of nonlinearity used.
- HS denotes h-swish and RE denotes ReLU.
- NBN denotes no batch normalization. s denotes stride.
使用 Stride 进行降采样,不使用 pooling。
Efficient Mobile Building Blocks
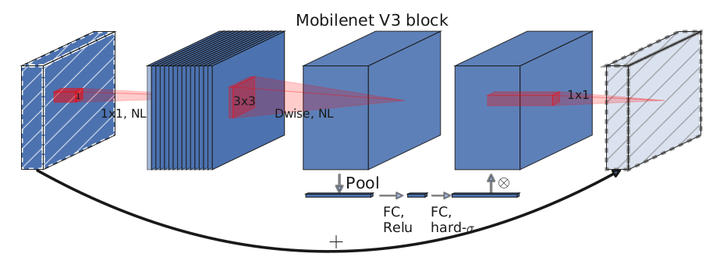
-
the linear bottleneck and inverted residual structure(V1)
-
depthwise separable convolutions (V2)
-
lightweight attention modules based on squeeze and excitation into the bottleneck structure
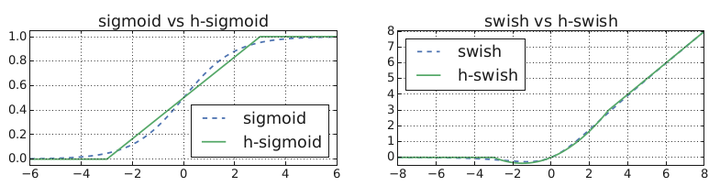
-
hard sigmoid:
-
Sigmoid:
- inefficient to compute
- challenging to maintain accuracy in fixed point arithmetic
- we change it to hard-sigmoid.
-
class hswish(nn.Module): def forward(self, x): out = x * F.relu6(x + 3, inplace=True) / 6 return out class hsigmoid(nn.Module): def forward(self, x): out = F.relu6(x + 3, inplace=True) / 6 return out
- Squeeze and Excite
Network Improvements
- Efficient last stage: